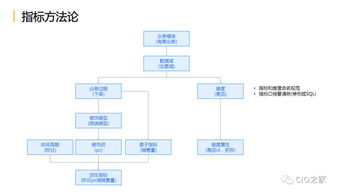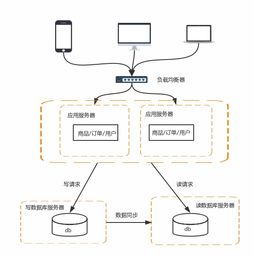
随着互联网的快速发展,数据服务逐渐成为互联网公司的核心支柱。为了应对用户规模的指数级增长和海量数据的处理挑战,互联网公司经历了从单机架构到分布式系统架构的演进过程。这一演进不仅提升了系统的可扩展性和可靠性,也推动了数据服务模式的创新。
在早期阶段,大多数互联网公司采用单机架构部署数据服务。这种架构简单易用,但存在明显的瓶颈:单点故障可能导致整个系统瘫痪,且处理能力受限于硬件性能。随着用户量的增加,单机架构很快无法满足高并发和数据处理的需求。
为了克服这些限制,互联网公司开始引入分布式系统架构。最初是通过垂直扩展,即增加服务器的硬件资源(如CPU、内存和存储),但这成本高昂且扩展性有限。水平扩展成为主流,通过多台服务器协同工作,将负载分散到不同节点上。这种架构不仅提高了系统的容错能力,还支持弹性伸缩,能够根据业务需求动态调整资源。
在数据服务领域,分布式架构的演进尤为显著。早期的分布式数据库和缓存系统(如MySQL主从复制、Memcached)解决了部分数据读写压力。随着大数据和实时数据处理需求的兴起,更复杂的分布式技术应运而生。例如,NoSQL数据库(如Cassandra、MongoDB)提供了高可扩展性和灵活的数据模型;分布式计算框架(如Hadoop、Spark)支持海量数据的批量处理和实时分析;微服务架构则允许将数据服务拆分为独立的模块,提升开发效率和系统维护性。
云原生和容器化技术(如Kubernetes、Docker)进一步推动了分布式系统架构的演进。这些技术使得数据服务可以更高效地部署和管理,支持自动扩缩容和故障恢复。边缘计算的兴起也为分布式数据服务提供了新的可能,通过将数据处理下沉到网络边缘,降低延迟并提升用户体验。
随着人工智能和5G技术的普及,互联网数据服务将继续深化分布式架构的应用。例如,联邦学习和去中心化数据存储可能成为新的趋势,在保障数据隐私的同时实现高效服务。分布式系统也带来了新的挑战,如数据一致性、系统复杂性和安全风险,这要求互联网公司在架构设计中不断优化和创新。
互联网公司分布式系统架构的演进之路是一条从简单到复杂、从集中到分散的路径。通过不断引入新技术和优化策略,数据服务得以支撑起日益复杂的业务场景,为用户提供更快速、可靠和智能的体验。